Generate a Synthetic Test Set¶
This tutorial guides you in creating a synthetic evaluation dataset for assessing your RAG pipeline. For this purpose, we will utilize OpenAI models. Ensure that your OpenAI API key is readily accessible within your environment.
import os
os.environ["OPENAI_API_KEY"] = "your-openai-key"
Documents¶
Initially, a collection of documents is needed to generate synthetic Question/Context/Ground_Truth samples. For this, we’ll use the LangChain document loader to load documents.
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("your-directory")
documents = loader.load()
Note
Each Document object contains a metadata dictionary, which can be used to store additional information about the document accessible via Document.metadata. Ensure that the metadata dictionary includes a key called filename, as it will be utilized in the generation process. The filename attribute in metadata is used to identify chunks belonging to the same document. For instance, pages belonging to the same research publication can be identified using the filename.
Here’s an example of how to do this:
for document in documents:
document.metadata['filename'] = document.metadata['source']
At this point, we have a set of documents ready to be used as a foundation for generating synthetic Question/Context/Ground_Truth samples.
Data Generation¶
Now, we’ll import and use Ragas’ TestsetGenerator to quickly generate a synthetic test set from the loaded documents.
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# generate testset
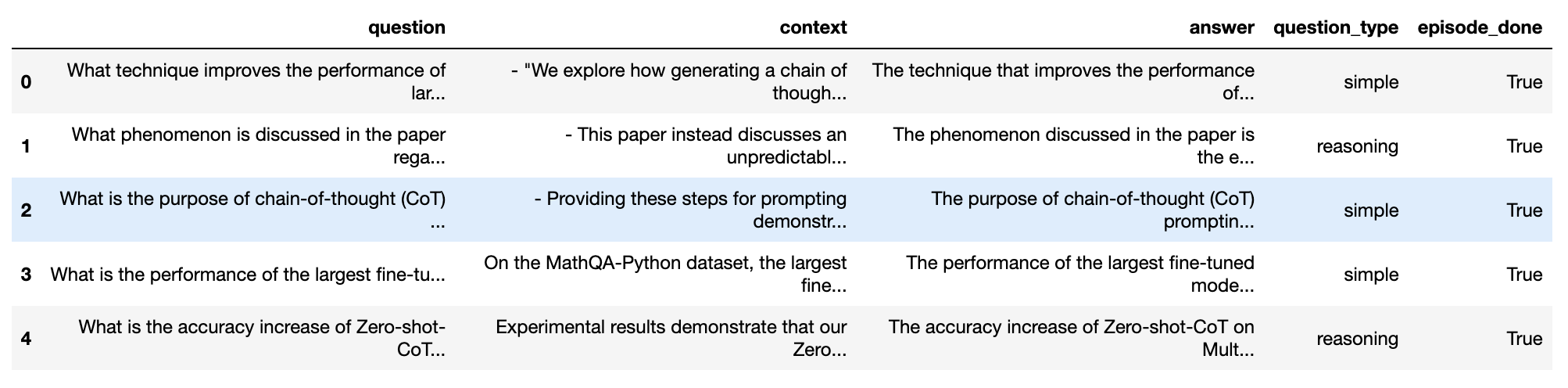
testset = generator.generate_with_langchain_docs(documents, test_size=10, distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25})
Then, we can export the results into a Pandas DataFrame.
testset.to_pandas()