Langfuse¶
Online Evaluation of RAG with Langfuse¶
Langfuse offers the feature to score your traces and spans. They can be used in multiple ways across Langfuse:
Displayed on trace to provide a quick overview
Segment all execution traces by scores to e.g. find all traces with a low-quality score
Analytics: Detailed score reporting with drill downs into use cases and user segments
Ragas is an open-source tool that can help you run Model-Based Evaluation on your traces/spans, especially for RAG pipelines. Ragas can perform reference-free evaluations of various aspects of your RAG pipeline. Because it is reference-free you don’t need ground-truths when running the evaluations and can run it on production traces that you’ve collected with Langfuse.
The Environment¶
import os
# TODO REMOVE ENVIRONMENT VARIABLES!!!
# get keys for your project from https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
# your openai key
# os.environ["OPENAI_API_KEY"] = ""
%pip install datasets ragas llama_index python-dotenv --upgrade
The Data¶
For this example, we are going to use a dataset that has already been prepared by querying a RAG system and gathering its outputs. See below for instruction on how to fetch your production data from Langfuse.
The dataset contains the following columns
question: list[str] - These are the questions your RAG pipeline will be evaluated on.answer: list[str] - The answer generated from the RAG pipeline and given to the user.contexts: list[list[str]] - The contexts which were passed into the LLM to answer the question.ground_truth: list[list[str]] - The ground truth answer to the questions. However, this can be ignored for online evaluations since we will not have access to ground-truth data in our case.
from datasets import load_dataset
amnesty_qa = load_dataset("explodinggradients/amnesty_qa", "english_v2")["eval"]
amnesty_qa
Found cached dataset amnesty_qa (/home/jjmachan/.cache/huggingface/datasets/explodinggradients___amnesty_qa/english_v2/2.0.0/d0ed9800191a31943ee52a5c22ee4305e28a33f5edcd9a323802112cff07cc24)
Dataset({
features: ['question', 'ground_truth', 'answer', 'contexts'],
num_rows: 20
})
The Metrics¶
For going to measure the following aspects of an RAG system. These metrics and from the Ragas library.
faithfulness: This measures the factual consistency of the generated answer against the given context.
answer_relevancy: Answer Relevancy, focuses on assessing how to-the-point and relevant the generated answer is to the given prompt.
context precision: Context Precision is a metric that evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Ideally, all the relevant chunks must appear at the top ranks. This metric is computed using the question and the contexts, with values ranging between 0 and 1, where higher scores indicate better precision.
aspect_critique: This is designed to assess submissions based on predefined aspects such as harmlessness and correctness. Additionally, users have the flexibility to define their own aspects for evaluating submissions according to their specific criteria.
Do refer the documentation to know more about these metrics and how they work docs
# import metrics
from ragas.metrics import faithfulness, answer_relevancy, context_precision
from ragas.metrics.critique import SUPPORTED_ASPECTS, harmfulness
# metrics you chose
metrics = [faithfulness, answer_relevancy, context_precision, harmfulness]
Now you have to initialize the metrics with LLMs and Embeddings of your choice. In this example lets use OpenAI.
from ragas.run_config import RunConfig
from ragas.metrics.base import MetricWithLLM, MetricWithEmbeddings
# util function to init Ragas Metrics
def init_ragas_metrics(metrics, llm, embedding):
for metric in metrics:
if isinstance(metric, MetricWithLLM):
metric.llm = llm
if isinstance(metric, MetricWithEmbeddings):
metric.embeddings = embedding
run_config = RunConfig()
metric.init(run_config)
from langchain_openai.chat_models import ChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings
# wrappers
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
llm = ChatOpenAI()
emb = OpenAIEmbeddings()
init_ragas_metrics(
metrics,
llm=LangchainLLMWrapper(llm),
embedding=LangchainEmbeddingsWrapper(emb),
)
The Setup¶
You can use model-based evaluation with Ragas in 2 ways
Score each Trace: This means you will run the evaluations for each trace item. This gives you much better idea since of how each call to your RAG pipelines is performing but can be expensive
Score as Batch: In this method we will take a random sample of traces on a periodic basis and score them. This brings down cost and gives you a rough estimate the performance of your app but can miss out on important samples.
In this cookbook, we’ll show you how to setup both.
Score with Trace¶
Lets take a small example of a single trace and see how you can score that with Ragas. First lets load the data
row = amnesty_qa[0]
print("question: ", row["question"])
print("answer: ", row["answer"])
question: What are the global implications of the USA Supreme Court ruling on abortion?
answer: The global implications of the USA Supreme Court ruling on abortion can be significant, as it sets a precedent for other countries and influences the global discourse on reproductive rights. Here are some potential implications:
1. Influence on other countries: The Supreme Court's ruling can serve as a reference point for other countries grappling with their own abortion laws. It can provide legal arguments and reasoning that advocates for reproductive rights can use to challenge restrictive abortion laws in their respective jurisdictions.
2. Strengthening of global reproductive rights movements: A favorable ruling by the Supreme Court can energize and empower reproductive rights movements worldwide. It can serve as a rallying point for activists and organizations advocating for women's rights, leading to increased mobilization and advocacy efforts globally.
3. Counteracting anti-abortion movements: Conversely, a ruling that restricts abortion rights can embolden anti-abortion movements globally. It can provide legitimacy to their arguments and encourage similar restrictive measures in other countries, potentially leading to a rollback of existing reproductive rights.
4. Impact on international aid and policies: The Supreme Court's ruling can influence international aid and policies related to reproductive health. It can shape the priorities and funding decisions of donor countries and organizations, potentially leading to increased support for reproductive rights initiatives or conversely, restrictions on funding for abortion-related services.
5. Shaping international human rights standards: The ruling can contribute to the development of international human rights standards regarding reproductive rights. It can influence the interpretation and application of existing human rights treaties and conventions, potentially strengthening the recognition of reproductive rights as fundamental human rights globally.
6. Global health implications: The Supreme Court's ruling can have implications for global health outcomes, particularly in countries with restrictive abortion laws. It can impact the availability and accessibility of safe and legal abortion services, potentially leading to an increase in unsafe abortions and related health complications.
It is important to note that the specific implications will depend on the nature of the Supreme Court ruling and the subsequent actions taken by governments, activists, and organizations both within and outside the United States.
Now lets init a Langfuse client SDK to instrument you app.
from langfuse import Langfuse
langfuse = Langfuse()
Here we are defining a utility function to score your trace with the metrics you chose.
async def score_with_ragas(query, chunks, answer):
scores = {}
for m in metrics:
print(f"calculating {m.name}")
scores[m.name] = await m.ascore(
row={"question": query, "contexts": chunks, "answer": answer}
)
return scores
question, contexts, answer = row["question"], row["contexts"], row["answer"]
await score_with_ragas(question, contexts, answer)
calculating faithfulness
calculating answer_relevancy
Using 'context_precision' without ground truth will be soon depreciated. Use 'context_utilization' instead
calculating context_precision
calculating harmfulness
{'faithfulness': 0.0,
'answer_relevancy': 0.9999999999999996,
'context_precision': 0.9999999999,
'harmfulness': 0}
You compute the score with each request. Below I’ve outlined a dummy application that does the following steps
gets a question from the user
fetch context from the database or vector store that can be used to answer the question from the user
pass the question and the contexts to the LLM to generate the answer
All these step are logged as spans in a single trace in langfuse. You can read more about traces and spans from the langfuse documentation.
# the logic of the dummy application is
# given a question fetch the correspoinding contexts and answers from a dict
import hashlib
def hash_string(input_string):
return hashlib.sha256(input_string.encode()).hexdigest()
q_to_c = {} # map between question and context
q_to_a = {} # map between question and answer
for row in amnesty_qa:
q_hash = hash_string(row["question"])
q_to_c[q_hash] = row["contexts"]
q_to_a[q_hash] = row["answer"]
# if your running this in a notebook - please run this cell
# to manage asyncio event loops
import nest_asyncio
nest_asyncio.apply()
from langfuse.decorators import observe, langfuse_context
from asyncio import run
@observe()
def retriver(question: str):
return q_to_c[question]
@observe()
def generator(question):
return q_to_a[question]
@observe()
def rag_pipeline(question):
q_hash = hash_string(question)
contexts = retriver(q_hash)
generated_answer = generator(q_hash)
# score the runs
score = run(score_with_ragas(question, contexts, answer=generated_answer))
for s in score:
langfuse_context.score_current_trace(name=s, value=score[s])
return generated_answer
question, contexts, answer = row["question"], row["contexts"], row["answer"]
generated_answer = rag_pipeline(amnesty_qa[0]["question"])
calculating faithfulness
calculating answer_relevancy
Using 'context_precision' without ground truth will be soon depreciated. Use 'context_utilization' instead
calculating context_precision
calculating harmfulness
Once the scores are computed you can add them to the trace in Langfuse:
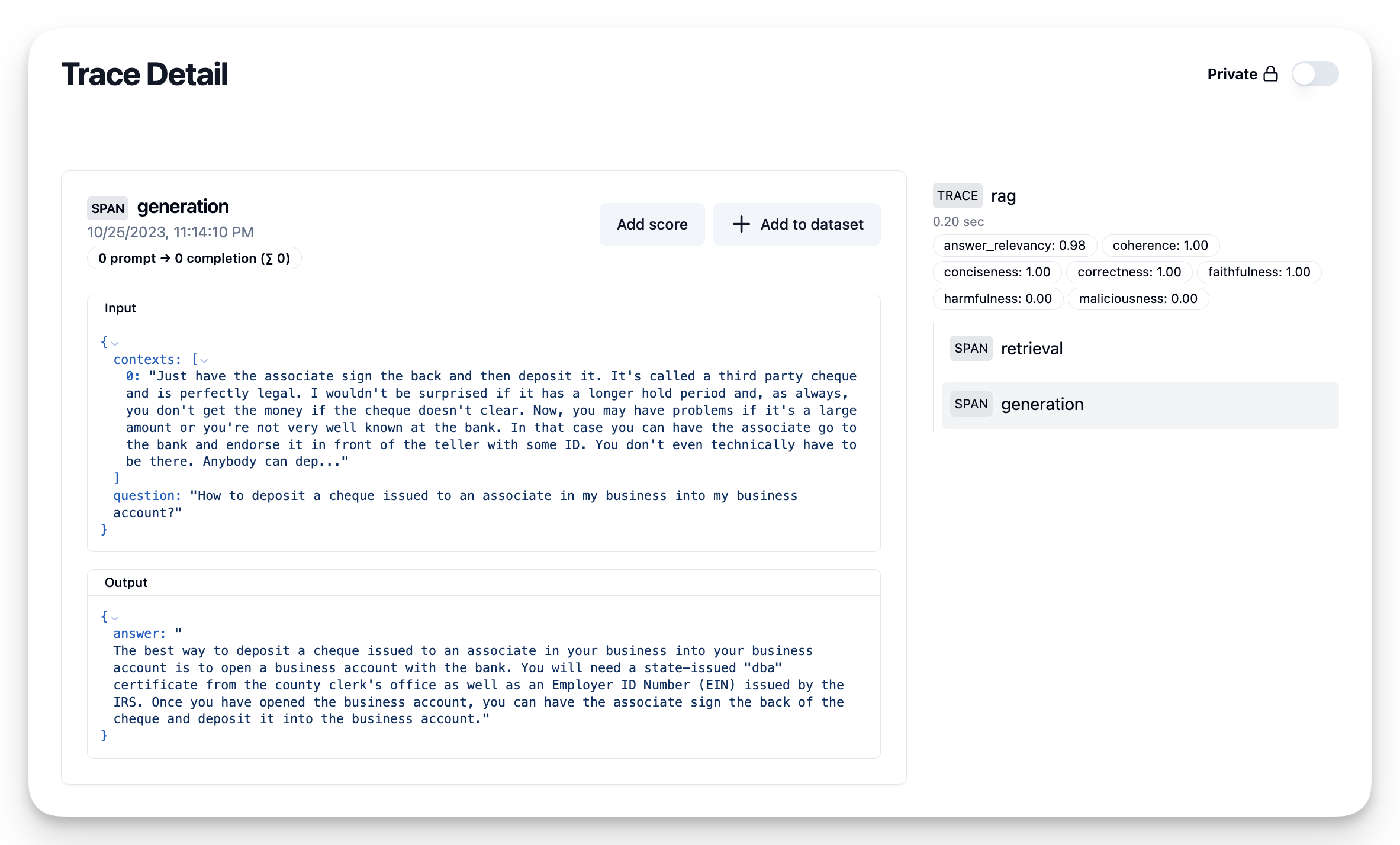
Note that the scoring is blocking so make sure that you sent the generated answer before waiting for the scores to get computed. Alternatively you can run score_with_ragas() in a separate thread and pass in the trace_id to log the scores.